- Prof. Dancy's Site - Course Site -
A Q learning example using Project Malmo

Quick recap of passive RL
We started looking at reinforcement learning from the perspective of passive reinforcement learning. In this formulation we have some set of policies that determine what action to take when we reach a certain state.
The figure below gives a 2d-map example of what this might look like.
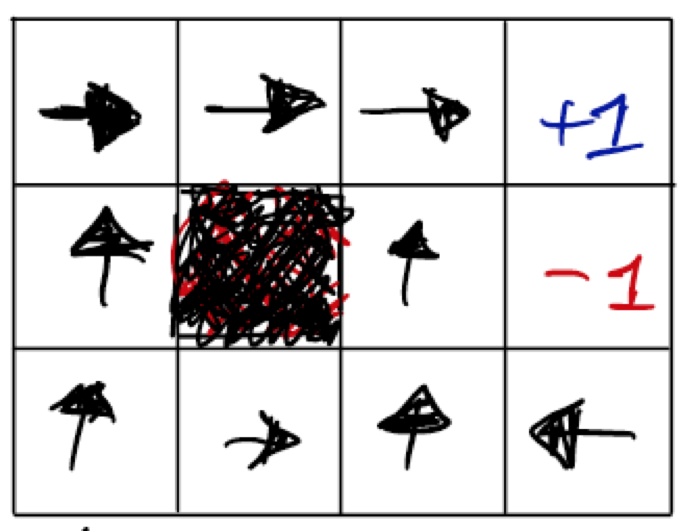
We'll use 2d maps to help us visualize things, but remember that the important parts are the _states_ and the _actions_ we take in these states. So, a state could represent anything from a position in a map to a position in space-time to a _mental state_ (e.g., cognitive architectures!)
Active RL
With active reinforcement learning, we are generally not trying to follow a specific policy, but are generating our policy on the fly! We are actively exploring the actions we should take given our current state. There are several types of active RL, many of which fall into the category of a temporal-difference learning algorithm (they learn the utility of states, or action-states in some time-dependent manner). We are going to go over a type of active reinforcement learning called Q-Learning.
Q-Learning finds the utility of action-state pairs. Essentially it not only learns the utility of reaching a certain state, but it also learns the utility of using a certain action in a given state. It begins to construct a transition model as it learns.
The figure below gives an idea of how we treat the action-state space with Q-learning. Now we are assigning utility to action state pairs.
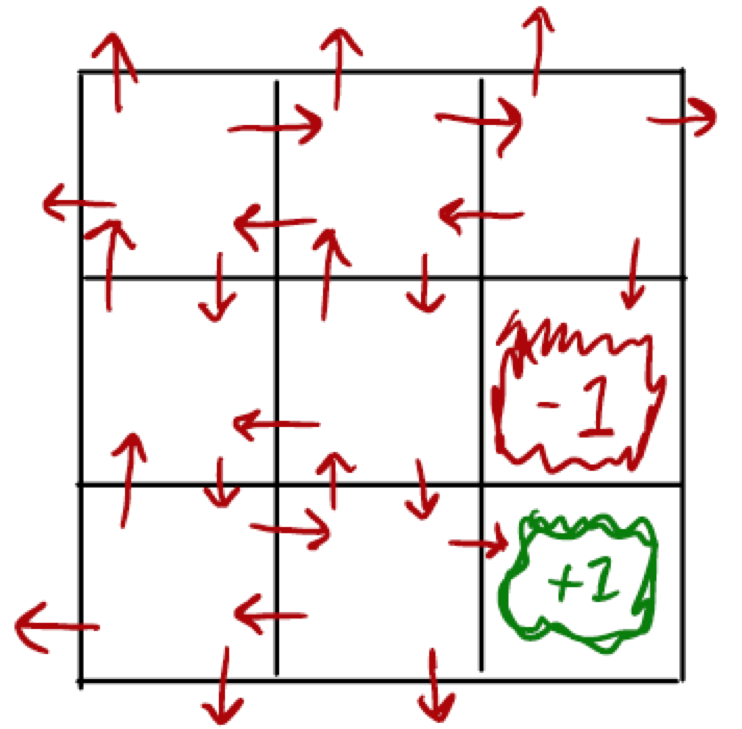
So now that we have a (very) high-level view of things, let's walk through the code and explain learning mechanisms along the way.
The Q Learning code in Minecraft
We will use Project Malmo (Minecraft) for our example. We'll create a Q-Learning agent that learns to move around in the environment and avoid certain death along the way (lava!).
Note that this code is modified from a tutorial in the Python Examples
The ActionJackson class
Let's have a look at our ActionJackson agent.

The initialization code is fairly straightforward. We initialize instance variables for our agent, some of which are for our agent learning and representation, and some of which are for showing a little visualization that will tell us how our agent is learning.
Here, alpha and gamma are learning parameters, while self.actions is a list of possible actions an agent can take in any given state. We also have a hash map (python dictionary) self.u_table where our key is a state representation, "x:z", and the value is a list of utility values (one for each action). Thus, our action is essentially tied to the same index for every list of every key. As a last note, we use self.epsilon below to introduce a bit of randomness to the selection process (think about it as a cheap way to get something like simulated annealing).
We'll use the term q-values instead of utility values as it's how you'd normally see those utility values described
class ActionJackson(TDAgent):
"""Tabular Q-learning agent for discrete state/action spaces."""
SCALE = 50
WORLD_X = 5
WORLD_Y = 5
def __init__(self, actions=[], epsilon=0.1, alpha=0.1, gamma=1.0, debug=False, canvas=None, root=None,seed=5):
super(QLAgent, self).__init__(actions, alpha, gamma, debug, canvas, root)
self.epsilon = epsilon
self.q_table = self.u_table
self.rnd = random.Random()
self.rnd.seed(5)
def load_model(self, model_file):
"""load q table from model_file"""
with open(model_file) as f:
self.q_table = json.load(f)
def training(self):
"""switch to training mode"""
self.training = True
def evaluate(self):
"""switch to evaluation mode (no training)"""
self.training = False
ActionJackson learns from his mistakes and takes instruction

The learn method below allows us to update q-values along the way using some of our parameters (alpha & gamma), some reward, and previous values for state-action values.
The equation we use to learn is q(s,a,t+1) = q(s,a,t) + alpha * (reward + gamma * max(q(s') - q(s,a,t)) where q(s,a,t+1) is the q-value for our state-action pair after update and q(s,a,t) is our current q-value for that state-action pair; old_q in the code below is used to represent q(s,a,t). As in previous representations, alpha is our learning rate, so the higher that is, the faster we learn new rewards. gamma is our discount factor that controls how much we take the utility of our next state into account. Notice that we take the max of our next state (s'), this allows us to consider the best possible case of using a state-action pair to move to a new state.
Unfortunately, there's a bit of an open issue with the way Project Malmo natively processes final states (where our agent quits). Thus, when we get to a terminal state, our equation changes slightly because there essentially isn't a next state, but instead only a reward. You'll also see in our act function that we have to change the reward in the case that we reach our goal, because the Malmo decorator we chose to help define our environment actually doesn't return a reward when we reach the goal.
def _learn(self, reward, terminal_state=True, current_s=None):
"""
The equation to learn in Q-learning
q(s,a,t+1) = q(s,a,t) + alpha * (reward + gamma * max(q(s') - q(s,a,t))
"""
if (terminal_state):
if (self.prev_s is not None and self.prev_a is not None):
old_q = self.q_table[self.prev_s][self.prev_a]
self.q_table[self.prev_s][self.prev_a] = old_q + self.alpha * ( reward - old_q )
else:
if (current_s is None):
print("Can't learn without knowing your current state!")
return
old_q = self.q_table[self.prev_s][self.prev_a]
self.q_table[self.prev_s][self.prev_a] = old_q + self.alpha * \
(reward + self.gamma * max(self.q_table[current_s]) - old_q)
ActionJackson acts on his instincts and his training

Now that we know how to learn, let's look at how ActionJackson goes about his acting. Let's find out more about his process.
In the code below, we use the the info_json parameter to get our current state (we would have used env to grab that info_json after a call to the step method in the env object). Once we get the current state, we can then update the q-value for the previous state-action pair (that led ActionJackson so the current state) using the learning methods discussed above.
def act(self, env, info_json, current_r ):
"""take action in response to the current world state"""
curr_x = int(info_json[u'XPos'])
curr_z = int(info_json[u'ZPos'])
current_s = "%d:%d" % (curr_x, curr_z)
if (not (current_s in self.q_table)):
self.q_table[current_s] = ([0] * len(self.actions))
# update Q values
if (self.training):
self._learn(current_r, True, current_s)
In the remaining code below, we update a small graphic representation that can be used to see how our agents q-values are changing.
We also, most importantly, determine our next action and carry out that action! Notice that we use self.epsilon below to allow a bit of randomness in the process. As in previous uses of randomness, we make sure to use an object that had a seed previous set so that we can reliably repeat any simulations and experiments we might want to run!
If we happen to have multiple state-actions pairs with the same q-value (same state, but different actions), we randomly select from those actions.
Once ActionJackson knows how to act, we have him jump into action by using the step method (env.step(a)). As a last thing, we save our state and action as self.prev_state and self.prev_a so that we can learn from our actions.
self.draw_q(curr_x = curr_x, curr_y = curr_z)
# select the next action
rnd_num = self.rnd.random()
if rnd_num < self.epsilon:
a = self.rnd.randint(0, len(self.actions) - 1)
else:
# Get the maximum q-value in the set of all possible actions from our current state
m = max(self.q_table[current_s])
l = list()
for x in range(0, len(self.actions)):
if self.q_table[current_s][x] == m:
l.append(x)
# If we have multiple actions w/ max value, then randomly select one
y = self.rnd.randint(0, len(l)-1)
a = l[y]
# send the selected action
(obs, reward, sim_done, info) = env.step(a)
time.sleep(0.01)
self.prev_s = current_s
self.prev_a = a
return (reward, sim_done, info)
ActionJackson gotta run

Now that we know how AJ learns and acts, we just have some last code to run the agent in the maze (I'll also give other needed code below, but won't walk through it).
After some small initializations, we see code that helps us understand what's going on in our world. env is the central object for communicating with Minecraft. As you might have guessed, calling step() allows us to continuously look for information from the server. This is useful as the system sometimes takes time (i.e., is delayed) when giving us information related to the current state of the environment.
Eventually, we get our initial position and then we start the process of performing acts while we're still receiving feedback from the world.
def run(self, env, info, reward):
"""run the agent on the world"""
total_reward = 0
current_r = reward
tol = 0.01
self.prev_s = None
self.prev_a = None
while (info is None or len(info) == 0):
(obs, current_r, sim_done, info) = env.step(4)
time.sleep(0.01)
info_json = json.loads(info)
prev_x = int(info_json[u'XPos'])
prev_z = int(info_json[u'ZPos'])
# get some info from an initial action
(current_r, sim_done, info) = self.act(env, info_json, current_r)
total_reward += current_r
require_move = True
check_expected_position = True
The main loop below is where our agent continuously gets feedback from the environment and completes an action.
Until the agent sends a quit command (via step) or the agent completes an action that resulted in a change in the Minecraft environment that is predetermined to warrant an agent quitting (e.g., touching a certain block type, which would be specified while constructing the mission).
Notice that our observation string, info, is in json format, so we use json.loads to process the string into an object that we can easily use. The rest of the method is using the methods we explained earlier.
while not sim_done:
#--- Wait for some info ---#
if (info is None or len(info) == 0):
(obs, current_r, sim_done, info) = env.step(4)
time.sleep(0.01)
#--- We received info, so continue on ---#
else:
# Get our position
info_json = json.loads(info)
curr_x = int(info_json[u'XPos'])
curr_z = int(info_json[u'ZPos'])
#--- We seem to run into an issue where the simulation isn't marked as done & we need to query again. ---#
(obs, current_r, sim_done, info) = env.step(4)
time.sleep(0.01)
print(info)
#------#
###--- If the simulation has completed, make sure we can assign a value to the action we completed from our current state
if (sim_done):
self.prev_s = "%d:%d" % (int(curr_x), int(curr_z))
if (not (self.prev_s in self.q_table)):
self.q_table[self.prev_s] = ([0] * len(self.actions))
break
#------#
#--- Check to see if the movement has been observed ---#
# Checks for an expected move that hasn't yet been represented on the information we've gotten back
# (and pings the server for the correct info)
expected_x = prev_x + [0,0,-1,1][self.prev_a]
expected_z = prev_z + [-1,1,0,0][self.prev_a]
while (math.hypot( curr_x - expected_x, curr_z - expected_z ) > 0.01 and (not sim_done)):
#print(' - ERROR DETECTED! Expected:',expected_x,',',expected_z)
(obs, current_r, sim_done, info) = env.step(4)
while ((info is None or len(info) == 0) and (not sim_done)):
(obs, current_r, sim_done, info) = env.step(4)
time.sleep(0.01)
# Case where we might have finished the sim, but not gotten actual info back
if (sim_done):
self.prev_s = "%d:%d" % (int(curr_x), int(curr_z))
if (not (self.prev_s in self.q_table)):
self.q_table[self.prev_s] = ([0] * len(self.actions))
break
info_json = json.loads(info)
curr_x = int(info_json[u'XPos'])
curr_z = int(info_json[u'ZPos'])
#------#
#--- If the simulation has completed, make sure we can assign a value to the action we completed from our current state ---#
if (sim_done):
self.prev_s = "%d:%d" % (int(curr_x), int(curr_z))
if (not (self.prev_s in self.q_table)):
self.q_table[self.prev_s] = ([0] * len(self.actions))
break
#------#
prev_x = curr_x
prev_z = curr_z
# act
(current_r, sim_done, info) = self.act(env, info_json, current_r)
total_reward += current_r
#--- Beceause we use the maze decorator...the correct reward isn't given on the final block...
# so we adjust for this by knowing that if it isn't a negative reward...we must have ended on the goal block. ---#
if (current_r > 0):
current_r = 100
#------#
# process final reward
print("Final reward: %d" % current_r)
print("Final Position: %d : %d" % (curr_x, curr_z))
# Update Q values, Note that this formula is slightly different than class
# This is because we are at a terminal state...so we need to just use the current reward
if (self.training):
self._learn(current_r, True)
self.draw_q(curr_x = int(curr_x), curr_y = int(curr_z))
return total_reward
And that's it for our class! It's a very simple agent that can learn a lot if you give it the right tools. If you can specify a range of actions and the state in a way that makes sense given the environment you can expand this agent in many ways.
If you wanted to expand, think about how you could have the agent accomplish more complex actions. What might you change on the action side? How might you make the state representation more complex?
Below is the further code you'll want to make this work. The draw_table method is below, as is the code from the MazeSimRL.py that I run to actually run the agent (which also sets up our environment with the corresponding XML).
def draw_q( self, curr_x=None, curr_y=None ):
if self.canvas is None or self.root is None:
return
self.canvas.delete("all")
action_inset = 0.1
action_radius = 0.1
curr_radius = 0.2
action_positions = [ ( 0.5, 1-action_inset ), ( 0.5, action_inset ), ( 1-action_inset, 0.5 ), ( action_inset, 0.5 ) ]
# (NSWE to match action order)
min_value = -100
max_value = 100
for x in range(QLAgent.WORLD_X):
for y in range(QLAgent.WORLD_Y):
s = "%d:%d" % (x,y)
self.canvas.create_rectangle( (QLAgent.WORLD_X-1-x)*QLAgent.SCALE, (QLAgent.WORLD_Y-1-y)*QLAgent.SCALE, (QLAgent.WORLD_X-1-x+1)*QLAgent.SCALE, (QLAgent.WORLD_Y-1-y+1)*QLAgent.SCALE, outline="#fff", fill="#000")
for action in range(4):
if not s in self.q_table:
continue
value = self.q_table[s][action]
#print(value)
color = 255 * ( value - min_value ) / ( max_value - min_value ) # map value to 0-255
color = math.ceil(max(min(color, 255),0)) # ensure within [0,255] & integer
color_string = '#%02x%02x%02x' % (255-color, 0, color)
self.canvas.create_oval( (QLAgent.WORLD_X - 1 - x + action_positions[action][0] - action_radius ) *QLAgent.SCALE,
(QLAgent.WORLD_Y - 1 - y + action_positions[action][1] - action_radius ) *QLAgent.SCALE,
(QLAgent.WORLD_X - 1 - x + action_positions[action][0] + action_radius ) *QLAgent.SCALE,
(QLAgent.WORLD_Y - 1 - y + action_positions[action][1] + action_radius ) *QLAgent.SCALE,
outline=color_string, fill=color_string )
if curr_x is not None and curr_y is not None:
self.canvas.create_oval( (QLAgent.WORLD_X - 1 - curr_x + 0.5 - curr_radius ) * QLAgent.SCALE,
(QLAgent.WORLD_Y - 1 - curr_y + 0.5 - curr_radius ) * QLAgent.SCALE,
(QLAgent.WORLD_X - 1 - curr_x + 0.5 + curr_radius ) * QLAgent.SCALE,
(QLAgent.WORLD_Y - 1 - curr_y + 0.5 + curr_radius ) * QLAgent.SCALE,
outline="#fff", fill="#fff" )
self.root.update()
MazeSimRL.py
# ------------------------------------------------------------------------------------------------
# Copyright (c) 2016 Microsoft Corporation
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
# associated documentation files (the "Software"), to deal in the Software without restriction,
# including without limitation the rights to use, copy, modify, merge, publish, distribute,
# sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all copies or
# substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT
# NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
# NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
# DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# ------------------------------------------------------------------------------------------------
# Dancy Oct-2019
# Can't seem to get the agent to actually reach the terminal/endblock
# (it seems to only get to the block before?) so unable to get the actual reward!
import malmoenv
import json
import math
import os
import random
import sys, argparse
import time
from RLAgents import *
import errno
if sys.version_info[0] == 2:
# Workaround for https://github.com/PythonCharmers/python-future/issues/262
import Tkinter as tk
else:
import tkinter as tk
save_images = False
if save_images:
from PIL import Image
class MazeSimRL:
MAP_SIZE = 6
MS_PER_TICK = 5
FLOOR_BLOCK = "sandstone"
GAP_BLOCK = "lava"
PATH_BLOCK = "stone"
START_BLOCK = "emerald_block"
END_BLOCK = "diamond_block"
GOAL_BLOCK = "gold_block"
DEFAULT_MAZE = '''
<MazeDecorator>
<SizeAndPosition length="''' + str(MAP_SIZE-1) + '''"\
width="''' + str(MAP_SIZE-1) + '''" \
yOrigin="225" zOrigin="0" height="180"/>
<GapProbability variance="0.4">0.1</GapProbability>
<Seed>10</Seed>
<MaterialSeed>random</MaterialSeed>
<AllowDiagonalMovement>false</AllowDiagonalMovement>
<StartBlock fixedToEdge="true" type="emerald_block" height="1"/>
<EndBlock fixedToEdge="true" type="''' + END_BLOCK + '''" height="1"/>
<SubgoalBlock type="''' + GOAL_BLOCK + '''" height="1"/>
<PathBlock type="''' + PATH_BLOCK + '''" colour="WHITE ORANGE MAGENTA LIGHT_BLUE YELLOW LIME PINK GRAY SILVER CYAN PURPLE BLUE BROWN GREEN RED BLACK" height="1"/>
<FloorBlock type="''' + FLOOR_BLOCK + '''" height="1"/>
<OptimalPathBlock type="stone" variant="smooth_granite andesite smooth_diorite diorite"/>
<GapBlock type="'''+ GAP_BLOCK + '''" height="1"/>
<AddQuitProducer description="finished maze"/>
</MazeDecorator>
'''
def __init__(self, agent=None, maze_str=None):
if (not(maze_str is None)):
self.__maze_str = maze_str
else:
self.__maze_str = MazeSimRL.DEFAULT_MAZE
self._agent = agent
# -- set up the python-side drawing -- #
(canvas, root) = self.setup_table_gfx()
if (self._agent is None):
actionSet = ["movenorth 1", "movesouth 1", "movewest 1", "moveeast 1"]
self._agent = QLAgent(
actions=actionSet,
epsilon=0.01,
alpha=0.1,
gamma=1,
debug = False,
canvas = canvas,
root = root)
def get_mission_xml(self):
return '''<?xml version="1.0" encoding="UTF-8" ?>
<Mission xmlns="http://ProjectMalmo.microsoft.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<About>
<Summary>Run the maze!</Summary>
</About>
<ModSettings>
<MsPerTick>''' + str(MazeSimRL.MS_PER_TICK) + '''</MsPerTick>
</ModSettings>
<ServerSection>
<ServerInitialConditions>
<AllowSpawning>false</AllowSpawning>
</ServerInitialConditions>
<ServerHandlers>
<FlatWorldGenerator generatorString="3;7,220*1,5*3,2;3;,biome_1" />
''' + self.__maze_str + '''
<ServerQuitFromTimeUp timeLimitMs="45000"/>
<ServerQuitWhenAnyAgentFinishes />
</ServerHandlers>
</ServerSection>
<AgentSection mode="Survival">
<Name>RL Smart Guy</Name>
<AgentStart>
<Placement x="1" y="81" z="1"/>
</AgentStart>
<AgentHandlers>
<VideoProducer want_depth="false">
<Width>640</Width>
<Height>480</Height>
</VideoProducer>
<ObservationFromFullStats/>
<DiscreteMovementCommands />
<RewardForMissionEnd>
<Reward description="found_goal" reward="100" />
<Reward description="out_of_bounds" reward="-1000" />
<Reward description="hot_fire" reward="-100" />
</RewardForMissionEnd>
<RewardForTouchingBlockType>
<Block type="gold_block" reward="3" />
<Block type="stone" reward="4" />
<!-- <Block type="diamond_block" reward="100" behaviour="onceOnly" />
<Block type="grass" reward="-1000" behaviour="onceOnly" />
<Block type="lava" reward="-100" behaviour="onceOnly" /> -->
</RewardForTouchingBlockType>
<RewardForSendingCommand reward="-2"/>
<AgentQuitFromTouchingBlockType>
<Block type="diamond_block" description="found_goal" />
<Block description="out_of_bounds" type="grass" />
<Block description="hot_fire" type="lava" />
</AgentQuitFromTouchingBlockType>
</AgentHandlers>
</AgentSection>
</Mission>'''
def setup_table_gfx(self):
scale = 50
world_x = MazeSimRL.MAP_SIZE
world_y = MazeSimRL.MAP_SIZE
root = tk.Tk()
title = str(type(self._agent)) + "-table"
root.wm_title(title)
canvas = tk.Canvas(root, width=(MazeSimRL.MAP_SIZE-1)*scale,
height=(MazeSimRL.MAP_SIZE-1)*scale, borderwidth=0, highlightthickness=0,
bg="black")
canvas.grid()
root.update()
return (canvas, root)
def run_sim(self, exp_role, num_episodes, port1, serv1, serv2, exp_id, epi, rsync):
if (self._agent is None):
print("Need to set an agent!")
return
env = malmoenv.make()
env.init(self.get_mission_xml(),
port1, server=serv1,
server2=serv2, port2=(port1 + exp_role),
role=exp_role,
exp_uid=exp_id,
episode=epi,
resync=rsync,
action_space = malmoenv.ActionSpace(self._agent.get_actions() + ["move 0"]))
expID = 'tabular_RL'
for i in range(num_episodes):
cumulative_rewards = []
print("Reset [" + str(exp_role) + "] " + str(i) )
movements = None
env.reset()
num_steps = 0
sim_done = False
total_reward = 0
total_commands = 0
#--- Dummy step so that we get some initial info from the environment ---#
(obs, reward, sim_done, info) = env.step(4)
time.sleep(0.01)
#------#
cumulative_reward = self._agent.run(env, info, reward)
print("Cumulative reward: %d" % cumulative_reward)
cumulative_rewards += [ cumulative_reward ]
print("Done.")
print("Cumulative rewards for all %d runs:" % num_episodes)
print(cumulative_rewards)
# Setup our Maze and run it
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='malmovnv test')
parser.add_argument('--port', type=int, default=9000, help='the mission server port')
parser.add_argument('--server', type=str, default='127.0.0.1', help='the mission server DNS or IP address')
parser.add_argument('--server2', type=str, default=None, help="(Multi-agent) role N's server DNS or IP")
parser.add_argument('--port2', type=int, default=9000, help="(Multi-agent) role N's mission port")
parser.add_argument('--episodes', type=int, default=2000, help='the number of resets to perform - default is 1')
parser.add_argument('--episode', type=int, default=0, help='the start episode - default is 0')
parser.add_argument('--resync', type=int, default=0, help='exit and re-sync on every N - default 0 meaning never')
parser.add_argument('--experimentUniqueId', type=str, default="tabular_RL", help="the experiment's unique id.")
args = parser.parse_args()
if args.server2 is None:
args.server2 = args.server
my_sim = MazeSimRL()
my_sim.run_sim(0, args.episodes, args.port, args.server, args.server2,
args.experimentUniqueId, args.episode, args.resync)